§ 5. Multiple View Geometry
In this section we study the relationship that links three or more views of the same 3-D scene, known in the three-view case as trifocal geometry.
This geometry could be described in terms of fundamental matrices linking pairs of cameras, but a more compact and elegant description is provided by a suitable trilinear form, in the same way as the epipolar (bifocal) geometry is described by a bilinear form.
We also discover that three views are all we need, in the sense that additional views do not allow us to compute anything we could not already compute (Section 5.4).
§ 5.1. Trifocal geometry
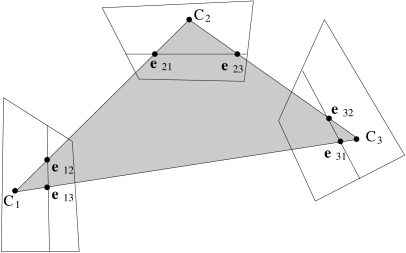
Denoting the cameras by
The plane containing the three optical centres is called the trifocal plane. It intersects each image plane along a line which contains the two epipoles.
Writing Eq. (45) for each camera pair (taking
the centre of the third camera as the point
| (64) |
Three fundamental matrices include 21 free parameters, less the 3 constraints above; the trifocal geometry is therefore determined by 18 parameters.
This description of the trifocal geometry fails when the three cameras are collinear, and the trifocal plane reduces to a line.
§ 5.1.1. Point transfer
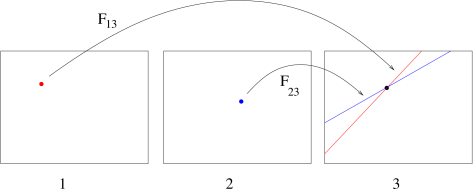
If the trifocal geometry is known, given two conjugate points
This allows for point transfer or prediction. Indeed,
| (65) |
View synthesisLaveau and Faugeras (1994); Avidan and Shashua (1997); Boufama (2000), exploit the trifocal geometry to generate novel (synthetic) images starting from two reference views. A related topic is image-based rendering(Lengyel,1998; Zhang and Chen,2003; Isgrò et al.,2004).
Epipolar transfer fails when the three optical rays are coplanar, because the epipolar lines are coincident. This happens:
-
if the 3-D point is on the trifocal plane;
-
if the three cameras centres are collinear (independently of the position of 3-D point).
These deficiencies motivate the introduction of an independent trifocal constraint.
In addition, by generalizing the case of two views, one might conjecture that the trifocal geometry should be represented by a trilinear form in the coordinates of three conjugate points.
§ 5.2. The trifocal constraint
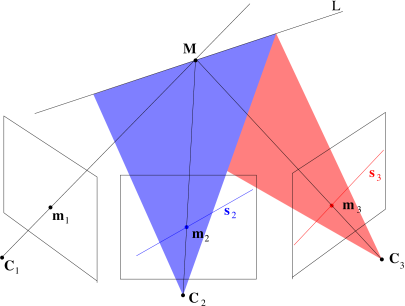
Consider a point
| (66) |
Let us write the epipolar line of
| (67) | ||||
| (68) |
where
Consider a line through
| (69) |
Likewise, for a line through
| (70) |
After eliminating
| (71) |
and after some re-writing:
| (72) |
This is the trifocal constraint, that links (via a
trilinear form)
Geometrically, the trifocal constraint imposes that the optical rays
of
Please note that given two (arbitrary) lines in two images, they can
be always seen as the image of a 3-D line
The trifocal constraint represents the trifocal geometry (nearly) without singularities. It only fails is when the cameras are collinear and the 3-D point is on the same line.
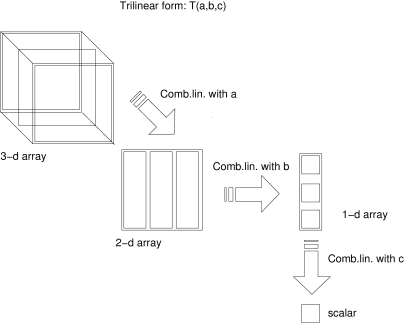
Using the properties of the Kronecker product, the trifocal constraint (Eq. (72)) can be written as:
| (73) |
where
| (74) |
The matrix
An equivalent formulation of the trifocal constraint that generalizes
the expression of a bilinear form (Cfr. pg. 4.5.2) is
obtained by applying once again the property
| (75) |
§ 5.2.1. Trifocal constraint for lines.
Consider a line
| (76) |
hence
| (77) |
This is the trifocal constraint for lines, which also allows direct
line transfer: if
§ 5.2.2. Trifocal constraints for points.
-
In Eq. (72),
-
Each row of
Hence we can write a total of nine constraints similar to Eq. (72), only four of which are independent (two for each point):
| (78) |
Hence, the trifocal constraints for three points writes:
| (79) |
Or, equivalently
| (80) |
This equation can be used to recover
Therefore, every triplet
§ 5.2.3. Point transfer.
A third equivalent formulation of the trifocal constraint is derived
if we look at the vector
| (81) |
where
By the same token as before, one can stack three equations similar to Eq. (81) as:
| (82) |
This implies that the transpose of the leftmost term in parentheses
(which is a 3-D vector) belongs to the kernel of
| (83) |
This is the point transfer equation: if
§ 5.2.4. Homography from the trifocal matrix
A line
Hence,
On the other hand, Eq. (77) is equivalent to
Hence, the homography
§ 5.2.5. Relationship with the trifocal tensor.
The Kronecker notation and the tensorial notation are deeply related,
as both represents multilinear forms. To draw this relationship in the
case of the trifocal geometry, let us expand the trifocal matrix into its columns
| (84) |
This implies that
The
§ 5.3. Reconstruction
As in the case of two views, what can be reconstructed depends on what is known about the scene and the cameras.
If the intrinsic parameters of the cameras are known, we can obtain a Euclidean reconstruction, that differs from the true reconstruction by a similarity transformation. This is composed by a rigid displacement (due to the arbitrary choice of the world reference frame) plus a a uniform change of scale (due to the well-known depth-speed ambiguity).
In the weakly calibrated case, i.e., when point correspondences are the only information available, a projective reconstruction can be obtained.
In both cases, the solution is not a straightforward generalization of the two view case, as the problem of global consistency comes into play (i.e., how to relate each other the local reconstructions that can be obtained from view pairs).
§ 5.3.1. Euclidean Reconstruction
Let us consider for simplicity the case of three views, which generalizes straightforward to N views.
If one applies the method of Section 4.4.2 to view pairs
1-2, 1-3 and 2-3 one obtains three displacements
The “true” displacements must satisfy the following compositional rule
| (85) |
which can be rewritten as
| (86) |
where
However, Eq. (85) constraints
| (87) |
And similarly for
In this way three consistent camera matrices can be instantiated.
Note that only ratios of translation norm can be computed, hence the global scale factor remains undetermined.
§ 5.3.2. Projective Reconstruction
If one applies the method of Section 4.5.3 to consecutive pairs of views, she would obtain, in general, a set of reconstructions linked to each other by an unknown projective transformation (because each camera pair defines its own projective frame).
The trifocal geometry could be used to link together consistently triplets of views. In Section 4.5.3 we saw how a camera pair can be extracted from the fundamental matrix. Likewise, a triplet of consistent cameras can extracted from the trifocal matrix (or tensor). The procedure is more tricky, though.
An elegant method for multi-image reconstruction was described in Sturm and Triggs (1996), based on the same idea of the factorization method of Tomasi and Kanade (1992).
Consider
| (88) |
can be written in matrix form:
| (89) |
In this formula the
If we assume for a moment that the projective depths
| (90) |
In the noise-free case,
| (91) |
The sought reconstruction is obtained by setting:
| (92) |
This reconstruction is unique up to a (unknown) projective
transformation. Indeed, for any non singular projective
transformation
Consistently, the choice to subsume
In presence of noise,
where
As the depth
An iterative solution is to alternate estimating
If
| (93) |
Starting from an initial guess for
-
Normalize
-
Factorize
-
If
-
Solve for
-
Update
-
Goto 1.
Step 1 is necessary to avoid trivial solutions (e.g.
This technique is fast, requires no initialization, and gives good results in practice, although there is no guarantee that the iterative process will converge. A provably convergent iterative method has been presented by Mahamud et al. (2001).
§ 5.4. Multifocal constraints
We outline here an alternative and elegant way to derive all the
meaningful multi-linear constraints on
| (94) |
By stacking all these equations we obtain:
| (95) |
This implies that the
The minors that does not contain at least one row from each camera are identically zero, since they contain a zero column.
If a minor contains only one row from some view, the image coordinate corresponding to this row can be factored out (using Laplace expansion along the corresponding column).
Hence, at least one row has to be taken from each view to obtain a meaningful constraint, plus another row from each camera to prevent the constraint to be trivially factorized.
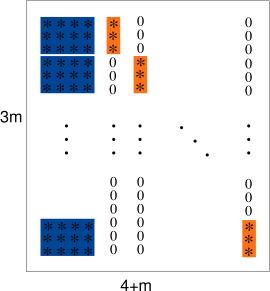
Since there are
-
Two rows from one view and two rows from another view.
-
Two rows from one view, one row from another view and one row from a third view.
-
One row from each of four different views.
If
If
If
If
This indicates that no interesting constraints can be written for more
than four views5
Please note that Eq. (95) can be also used
to triangulate one point